

In this blog, Dr. Israat Haque will cover some of the efforts to develop reliable SDNs and ensure high-quality services for end-users. Dr. Israat Haque joined Dalhousie University as an Assistant Professor in the Faculty of Computer Science in August 2017, where she created and started the Programmable and Intelligent Networking (PINet) research lab. Her research focus broadly includes the performance, security, and reliability aspects of Software-Defined Networking (SDN) and the Internet of Things (IoT). She was an NSERC post-doctoral researcher in the Department of Computer Science and Engineering at the University of California, Riverside (UCR) before joining Dalhousie.
In addition to NSERC post-doctoral fellowship, Dr. Haque received the ACM Anita Borg Institute Faculty and IEEE Senior member awards. She is an Associate Technical Editor (ATE) of the IEEE Communications Magazine (ComMag) and served as an area editor of the IEEE Transactions on Vehicular Technology from 2018 to 2020. She has been on the organizing committee of IEEE ICNP, IEEE NetSoft, IEEE CNSM, IFIP/IEEE Networking, and IEEE CloudNet and has also been serving as a TPC member in IEEE ICNP, ICC, NetSoft, WCNC, Globecom, and CNSM. Dr. Haque was the IEEE Computer and Communications Chapter chair of the Northern Canada Section for two years.
Let’s hear from Dr. Israat!
Communication Reliability in a Hyperconnected World
United Nations (UNO) estimates that more than half of the world’s population (above 4 billion people) is connected to the Internet today. By 2025, that will represent more than 40 billion devices embedded with connected sensors [1, 2]. Such connectivity will increasingly be an essential part of our everyday life that we rely on: everything from the cars we drive, the pills we take, and how we work and consume information.
Network reliability matters
A communication network should never go wrong irrespective of any unexpected physical or cyber events (e.g., a link down or fluctuations in traffic demand) to integrate networking into such critical applications. Still, in practice, we often experience failures of software, hardware, or communication links that disrupt our ongoing services. A long-term observation study on Google’s private networks reveals that 80% of their failures last between 10 to 100 minutes, creating significant packet losses resulting in serious issues experienced by users [3].
Over the last decade, Software-Defined Networking (SDN) has revolutionized how we configure and manage connected devices and the networking equipment that routes their data. The idea of a logically centralized controller with a global network view opened up numerous opportunities: to concisely specify complex network behaviors, observe traffic at various granularities, and quickly adapt to new network conditions. As a result, we have seen fast SDN adoption from the industry and are currently transitioning to the point where we primarily rely on them to keep our lives connected to the world.
Traffic engineering plays a crucial role
A primary tool at the heart of any SDN-based network reliability systems (both proactive and reactive) is traffic engineering (TE). TE accommodates traffic demands whenever a failure happens. In every TE cycle (usually 5 mins), routes between ingress and egress switches and corresponding rates are determined based on the traffic demands and the network state. A failure recovery scheme must be fast and topology agnostic while efficiently utilizing switch-memory and link-capacity to meet the QoS demand of serving applications; however, the design criteria are still missing from the existing solutions. SafeGuard, a TE-based proactive recovery approach in SD-WAN that is resource-efficient (capacity and memory), topology agnostic, and QoS-aware fill that gap. It defines the recovery problem as a Mixed Integer Linear Programming (MILP) optimization and develops a heuristic to solve the problem quickly. In particular, given a topology and routes (shortest, edge-disjoint, oblivious, etc.) among switches, SafeGuard minimizes the maximum link utilization across the network and the backup route-length.
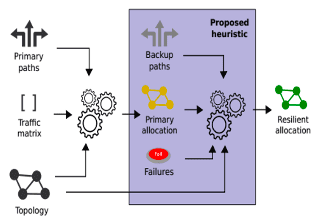
Furthermore, it allows a network operator to specify different priorities for route-length and link utilization. Fig. 1 presents SafeGuard architecture. The heuristic takes routes and traffic metrics (e.g., demand) as input to generate traffic rate allocation and backup route construction. Evaluation results of the SafeGuard prototype (which is publicly available) over multiple real network topologies and traffic load confirms that SafeGuard performs better in link utilization, backup route length, and memory usage over state-of-the-art design.
We also need reliable network telemetry systems
TE requires accurate tracking of the network state and the onset of failure: detecting, diagnosing, and even mitigating a failure before it causes any harm requires a good understanding of the network state acquired by measuring, collecting, and processing sufficient telemetry data. While traffic engineering is at the heart of any network reliability approach, this network telemetry is its bloodline. SDNs provide the flexibility of transforming any network device into a potent network monitor (e.g., one can collect a plethora of network statistics from current OpenFlow or P4 switches). Still, there is little effort in ensuring that these collecting agents will not fail. That is, our reliability mechanisms themselves may not be reliable!
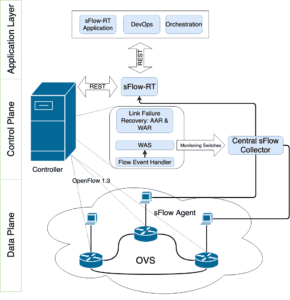
To fill this gap, we developed ReMon (or the “Resilient Monitoring framework”), a seminal network telemetry system augmented with a hybrid failure recovery scheme to be both resilient to failures and offer accurate and cost-effective telemetry. Fig. 2 presents ReMon architecture. A sFlow agent collects measurements from designated switches and passes them to the network controller, which deploys the proposed failure recovery algorithms (WAR, AAR) to redirect traffic in the presence of device or link failures. More importantly, the controller runs a switch selection algorithm, Weight Assisted Selecting (WAS), to choose the optimal number of switches that aggregate network telemetry on behalf of other switches. ReMon reduces the measurement traffic volume at these devices by aggregating traffic without compromising the measurement accuracy. Besides, it ensures that the telemetry traffic reaches the collector reliably.
Leveraging machine intelligence to work on the problem
We have discussed the heart and the bloodline: a missing piece of this intricate puzzle is the brain. Whenever a failure happens, it starts a complicated process for diagnosing and repairing its root causes. Even when a proactive recovery scheme is in place (e.g., a backup path to reroute traffic), network providers still need to repair the failing point to re-establish the regular network operating conditions. Therefore, considering the huge and ever-increasing scale of our hyperconnected world, it is not feasible to rely solely on humans to take care of this task anymore.
For this reason, in a first-of-its-kind effort, we developed PIQoS, a machine learning-based system for link failure detection targeted to Internet Service Providers (ISPs). PIQoS uses traffic flow stats among communicating pairs from ISP networks and employs a two-step process: first, it uses supervised machine learning algorithms (e.g., DT, RF, SVM, etc.) to train a model to distinguish between normal and anomalous network behavior, leading to a decision on whether a failure has occurred. Evaluation results on real ISP topologies indicate that learning-based failure detection is faster than traditional recovery schemes.
A look to the horizon
Network reliability usually evolves around new design paradigms, tools, and techniques. In this era of a hyperconnected world, the volume of network traffic from myriad applications is immense. Thus, designing data-driven network reliability systems seems a natural path to follow, where the data can represent software bugs, controller, hardware, and communication channel failures. The system should also avoid modification in switch architectures; rather, it must be hardware agnostic. The emerging data plane programmability (PISA architecture and P4 programming language) creates a new platform for designing fast (order of microseconds), scalable, and agile packet processing. Thus, another avenue to explore includes designing recovery systems exploiting programmable data planes.
**Statements and opinions given in this blog are the expressions of the contributor(s). Responsibility for the content of published articles rests upon the contributor(s), not on the IEEE Communication Society or the IEEE Communications Society Young Professionals.