

In this blog, Dr. Haijun Zhang (M’13, SM’17) will discuss the AI aided resource allocation for future mobile networks. Dr. Haijun Zhang is currently a Full Professor at the University of Science and Technology in Beijing, China, where he is the Associate Dean in the Graduate School of Artificial Intelligence. He was a Postdoctoral Research Fellow in the Department of Electrical and Computer Engineering, the University of British Columbia (UBC), Canada. He serves/served as an Editor of IEEE Transactions on Communications, IEEE Transactions on Green Communications Networking, and IEEE Communications Letters. He received the IEEE CSIM Technical Committee Best Journal Paper Award in 2018, IEEE ComSoc Young Author Best Paper Award in 2017, and IEEE ComSoc Asia-Pacific Best Young Researcher Award in 2019.
This article is based on the paper by Dr. Haijun Zhang and his collaborator published in IEEE Vehicular Technology Magazine.
Let’s hear from Dr. Haijun!
Next-generation (B5G/6G) mobile networks are characterized by three key features: (i) heterogeneity, in terms of technology and services, (ii) dynamics, in terms of rapidly varying environments and uncertainty, and (iii) size, in terms of the number of users, nodes, and services. For cellular systems, to achieve higher data rates while retaining the seamless connectivity and mobility of cellular networks, robust network resource allocation schemes are needed. For complex networks, traditional resource optimization algorithms may bring substantial computational complexity. Therefore, artificial intelligence-based resource allocation schemes have attracted intense interest. Compared with the conventional resource optimization schemes, which take a lot of time to calculate, artificial intelligence-based resource allocation schemes can make predictions from historical data.
Supervised learning
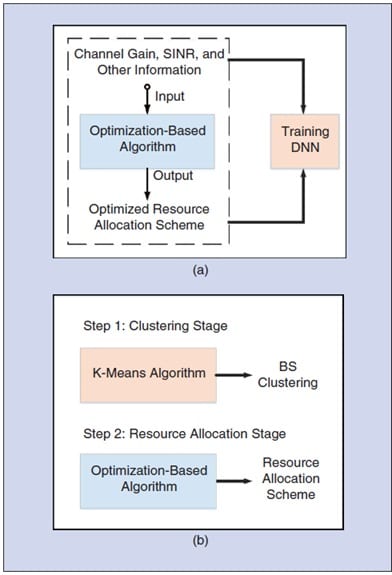
Deep neural networks (DNNs) helps to better-perform supervised learning. As shown in Fig. 1(a), we require the traditional resource optimization algorithms’ input and output values (such as the water-filling algorithm) as training data sets to apply DNNs in resource allocation. DNNs have to learn from the existing optimization algorithms first and then implement optimization by approximating the current optimization algorithms. If a DNN algorithm can perform the approximation accurately, it can replace the corresponding complex optimization algorithms.
Supervised learning-based resource allocation schemes rely on the training sets obtained from traditional resource optimization schemes. However, it is usually challenging for complex networks to get resource allocation algorithms through conventional optimization approaches.
Unsupervised learning
The K-means is a widely used unsupervised learning clustering algorithm. It uses the characteristics of samples to classify those with many similarities into the same category. Fig. 1(b) illustrates a resource management scheme’s steps based on a K-means clustering algorithm. Due to the different coverage and transmission power of varying base stations (BSs) in the network, the K-means algorithm divides BSs into multiple clusters. Similarly, users are grouped as per the interference among them in each BS cluster. After clustering, other algorithms help to allocate resources. This way, clustering algorithms reduce resource allocation complexity.
However, the development of collaborating resource allocation algorithms is a challenge. Even after clustering, in complex networks, resource allocation schemes based on the traditional optimization approaches may still have the problem of high complexity.
Reinforcement learning
Q-learning is the most common algorithm in reinforcement learning. Q-learning’s basic idea is to train the tuples composed of the state, action, reward, and the next state. In the Q-learning algorithm, a Q-table is constructed between the state and action to store the Q-values, which are the reward for taking action at a specific time plus the maximum expected value for the next step. The action obtaining the greatest reward is selected according to the Q-value to get as much return as possible. At each time slot, the agent first observes the environment and then performs actions to interact with it. After executing an action, the environment changes, and the reward expresses the quality of those changes returned from the environment. Therefore, the purpose of Q-learning is to get as much reward as possible. By regarding the network users as agents, the wireless environment (such as channels and powers for users) as the states, the network merits as rewards, and the resource allocation policies as actions, one can apply Q-learning to develop resource allocation algorithms.
Nevertheless, in Q-learning based resource allocation schemes, the resource allocation policies need to be conducted in each time slot. If the number of users in the system is large, the periodic policy search will occupy specific computing resources.
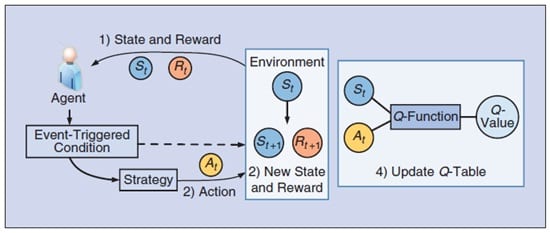
To reduce the complexity, in our recent work, we propose an Event-Triggered Q-learning based resource allocation. Fig. 2 illustrates the process of an event-triggered Q-learning algorithm. Each agent observes the environment information, state, and reward. Then, the agent needs to determine whether the event-triggered condition is satisfied before updating the strategy. If the condition is satisfied, the agent will find the optimal strategy and update the action based on current information. Otherwise, it will go directly to the next step, and the state will be the same as before. After interacting with the environment, we obtain the next state and reward. Finally, the agent updates the Q-table. We observe the effectiveness of the proposed scheme in our work.
Takeaway points
In summary, the artificial intelligence-based recourse allocation can be seen as an alternative or complement to the traditional recourse allocation schemes and is of great importance. The supervised learning-based, unsupervised learning, and reinforcement learning-based schemes have their advantages and disadvantages. Hence, we need more investigation in this area.
**Statements and opinions given in this blog are the expressions of the contributor(s). Responsibility for the content of published articles rests upon the contributor(s), not on the IEEE Communication Society or the IEEE Communications Society Young Professionals.
Author
Haijun Zhang, Professor, IEEE Senior Member
Associate Dean, Graduate School of Artificial Intelligence,
University of Science and Technology Beijing,
Beijing 100083, China.
Email: haijunzhang@ieee.org